Mor VenturaHello there! I'm a PhD candidate under the supervision of Prof. Roi Reichart in the Technion. I am interested in multimodal alignment, ensuring that what we ask of the model is exactly what we get. |

|
ResearchI am deeply interested in the intersection of vision and language, as well as commonsense reasoning. My recent research focuses on challenging the visual reasoning capabilities of models, particularly in abductive reasoning. Some papers are highlighted. |

|
Editor's Choice: Evaluating Abstract Intent in Image Editing through Atomic Entity Analysis
Mor Ventura, Roy Hirsch, Yonatan Bitton, Regev Cohen, Roi Reichart under submission, arXiv preprint, 2026 arXiv Humans naturally communicate through abstract concepts like "mood". However, current image editing benchmarks focus primarily on explicit, literal commands, leaving abstract instructions largely underexplored. In this work, we first formalize the definition and taxonomy of abstract image editing. To measure instruction-following in this challenging domain, we introduce Entity-Rubrics, a framework that breaks down abstract edits into individual, entity-level assessments and achieves strong correlation with human judgment. Alongside this framework, we contribute AbstractEdit, the first benchmark dedicated to abstract image editing across diverse real-world scenes. Evaluating 11 leading models on this dataset reveals a fundamental challenge: standard architectures struggle to balance intent and preservation, commonly defaulting to under-editing or over-editing. Our analysis demonstrates that driving meaningful improvements relies heavily on integrating advanced LLM text encoders and iterative thinking. Looking forward, our entity-based paradigm can generalize beyond assessment to serve as a reward model, enable models to correctly interpret abstract communication, or highlight specific failures in test-time critique loops. Ultimately, we hope this work serves as a stepping stone toward seamless multimodal interaction, closing the gap between rigid machine execution and the natural, open-ended way humans communicate. |
|
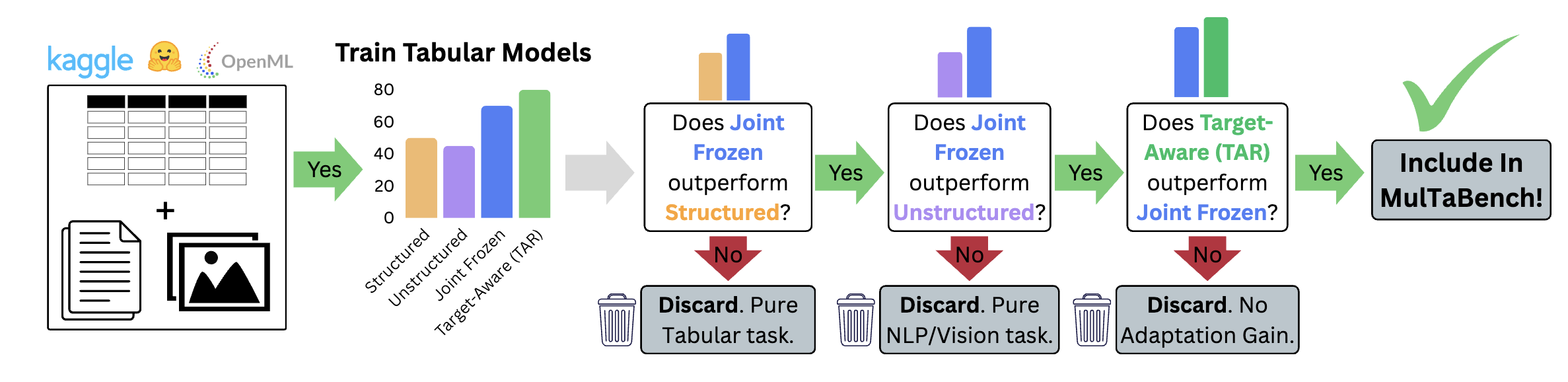
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
Alan Arazi*, Eilam Shapira*, Shoham Grunblat, Mor Ventura, Elad Hoffer, Gioia Blayer, David Holzmüller, Lennart Purucker, Gaël Varoquaux, Frank Hutter, Roi Reichart arXiv preprint, 2026 arXiv Tabular Foundation Models have recently established the state of the art in supervised tabular learning, by leveraging pretraining to learn generalizable representations of numerical and categorical structured data. However, they lack native support for unstructured modalities such as text and image, and rely on frozen, pretrained embeddings to process them. On established Multimodal Tabular Learning benchmarks, we show that tuning the embeddings to the task improves performance. Existing benchmarks, however, often focus on the mere co-occurrence of modalities; this leads to high variance across datasets and masks the benefits of task-specific tuning. To address this gap, we introduce MulTaBench, a benchmark of 40 datasets, split equally between image-tabular and text-tabular tasks. We focus on predictive tasks where the modalities provide complementary predictive signal, and where generic embeddings lose critical information, necessitating Target-Aware Representations that are aligned with the task. Our experimental results demonstrate that the gains from target-aware representation tuning generalize across both text and image modalities, several tabular learners, encoder scales, and embedding dimensions. MulTaBench constitutes the largest image-tabular benchmarking effort to date, spanning high-impact domains such as healthcare and e-commerce. It is designed to enable the research of novel architectures which incorporate joint modeling and target-aware representations, paving the way for the development of novel Multimodal Tabular Foundation Models. |
|
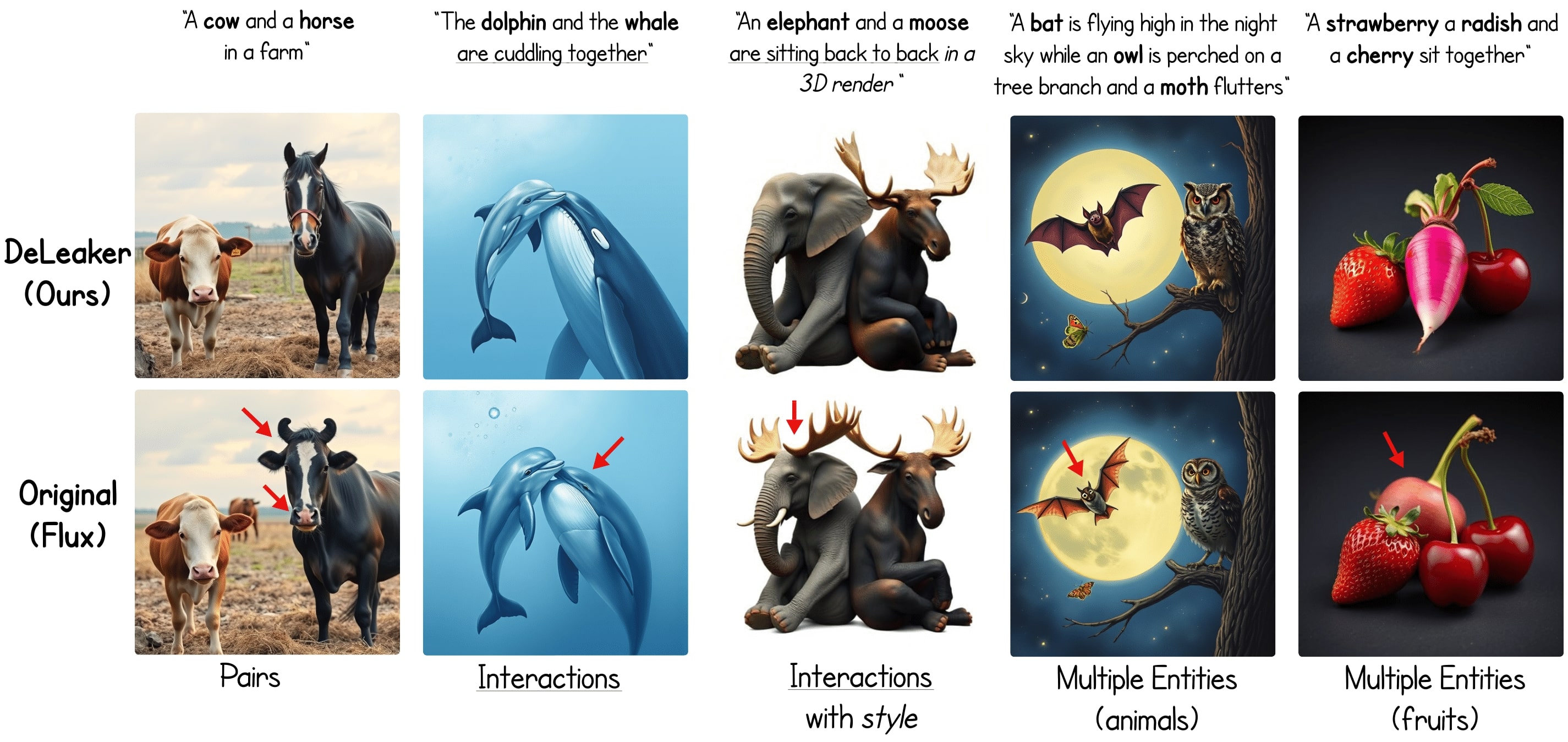
DeLeaker: Dynamic Inference-Time Reweighting For Semantic Leakge Mitigation In Text-to-Image Models
Mor Ventura*, Michael Toker*, Or Patashnik, Yonatan Belinkov, Roi Reichart, ICLR, 2026 project page / arXiv Text-to-Image (T2I) models have advanced rapidly, yet they remain vulnerable to semantic leakage, the unintended transfer of semantically related features between distinct entities. Existing mitigation strategies are often optimization-based or dependent on external inputs. We introduce DeLeaker, a lightweight, optimization-free inference-time approach that mitigates leakage by directly intervening on the model’s attention maps. Throughout the diffusion process, DeLeaker dynamically reweights attention maps to suppress excessive cross-entity interactions while strengthening the identity of each entity. To support systematic evaluation, we introduce SLIM (Semantic Leakage in IMages), the first dataset dedicated to semantic leakage, comprising 1,130 human-verified samples spanning diverse scenarios, together with a novel automatic evaluation framework. Experiments demonstrate that DeLeaker consistently outperforms all baselines, even when they are provided with external information, achieving effective leakage mitigation without compromising fidelity or quality. These results underscore the value of attention control and pave the way for more semantically precise T2I models. |

|
NL-EYE: Abductive NLI For Images
Mor Ventura, Michael Toker, Nitay Calderon, Zorik Gehkman, Yonatan Bitton, Roi Reichart, ICLR, 2025 project page / arXiv Will a Visual Language Model (VLM)-based bot warn us about slipping if it detects a wet floor? Recent VLMs have demonstrated impressive capabilities, yet their ability to infer outcomes and causes remains underexplored. To address this, we introduce NL-Eye, a benchmark designed to assess VLMs' visual abductive reasoning skills. NL-Eye adapts the abductive Natural Language Inference (NLI) task to the visual domain, requiring models to evaluate the plausibility of hypothesis images based on a premise image and explain their decisions. NL-Eye consists of 350 carefully curated triplet examples (1,050 images) spanning diverse reasoning categories: physical, functional, logical, emotional, cultural, and social. The data curation process involved two steps - writing textual descriptions and generating images using text-to-image models, both requiring substantial human involvement to ensure high-quality and challenging scenes. Our experiments show that VLMs struggle significantly on NL-Eye, often performing at random baseline levels, while humans excel in both plausibility prediction and explanation quality. This demonstrates a deficiency in the abductive reasoning capabilities of modern VLMs. NL-Eye represents a crucial step toward developing VLMs capable of robust multimodal reasoning for real-world applications, including accident-prevention bots and generated video verification. |
|
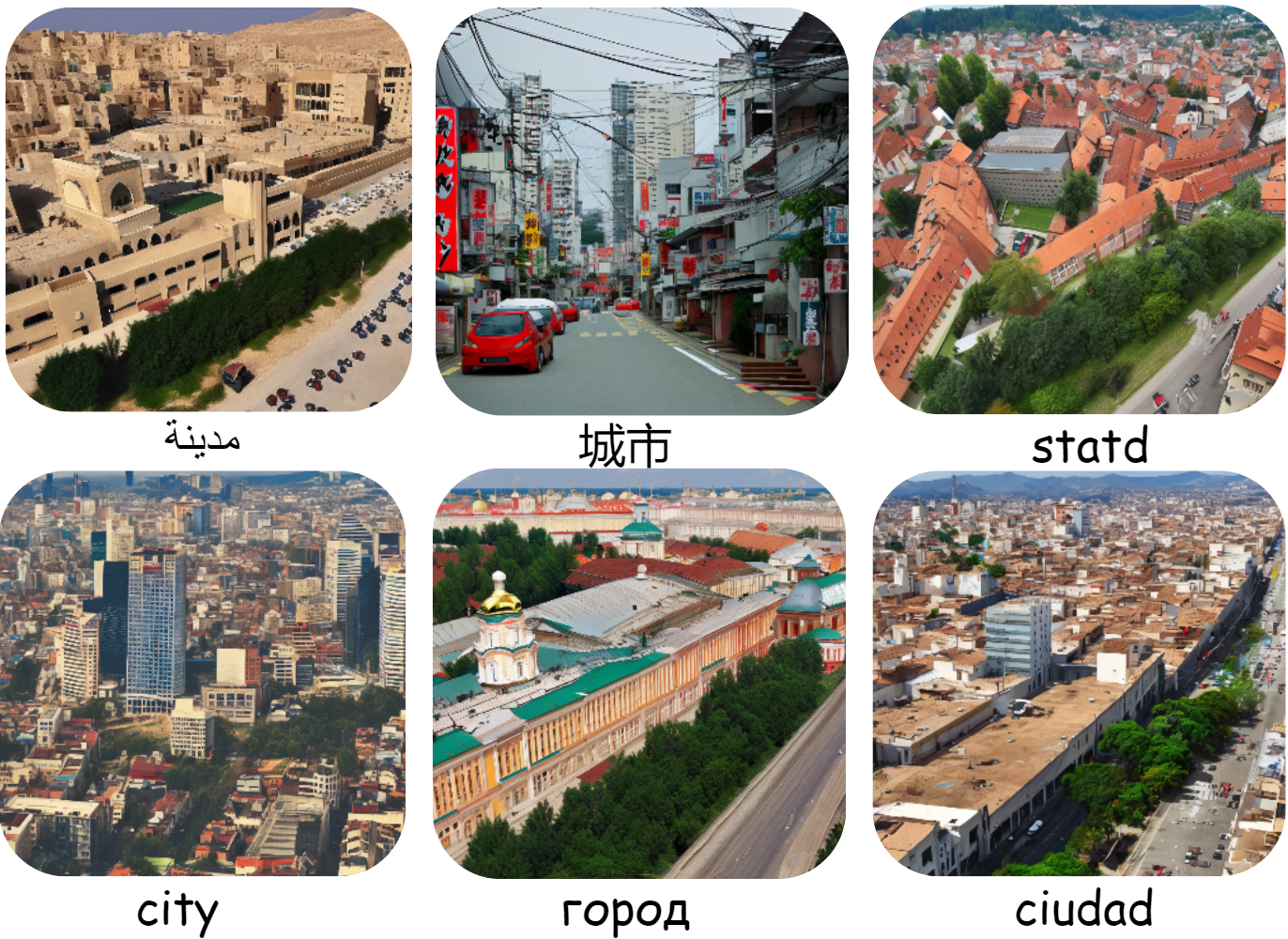
Navigating Cultural Chasms: Exploring and Unlocking the Cultural POV of Text-To-Image Models
Mor Ventura, Eyal Ben David, Anna Korhonen, Roi Reichart, TACL, 2024 (TACL journal | NAACL 2025 oral | ISCOL 2024 oral) project page / arXiv / MIT Press Text-To-Image (TTI) models, such as DALL-E and StableDiffusion, have demonstrated remarkable prompt-based image generation capabilities. Multilingual encoders may have a substantial impact on the cultural agency of these models, as language is a conduit of culture. In this study, we explore the cultural perception embedded in TTI models by characterizing culture across three hierarchical tiers: cultural dimensions, cultural domains, and cultural concepts. Based on this ontology, we derive prompt templates to unlock the cultural knowledge in TTI models, and propose a comprehensive suite of evaluation techniques, including intrinsic evaluations using the CLIP space, extrinsic evaluations with a Visual-Question-Answer (VQA) model and human assessments, to evaluate the cultural content of TTI-generated images. To bolster our research, we introduce the CulText2I dataset, derived from six diverse TTI models and spanning ten languages. Our experiments provide insights regarding Do, What, Which and How research questions about the nature of cultural encoding in TTI models, paving the way for cross-cultural applications of these models. |
|
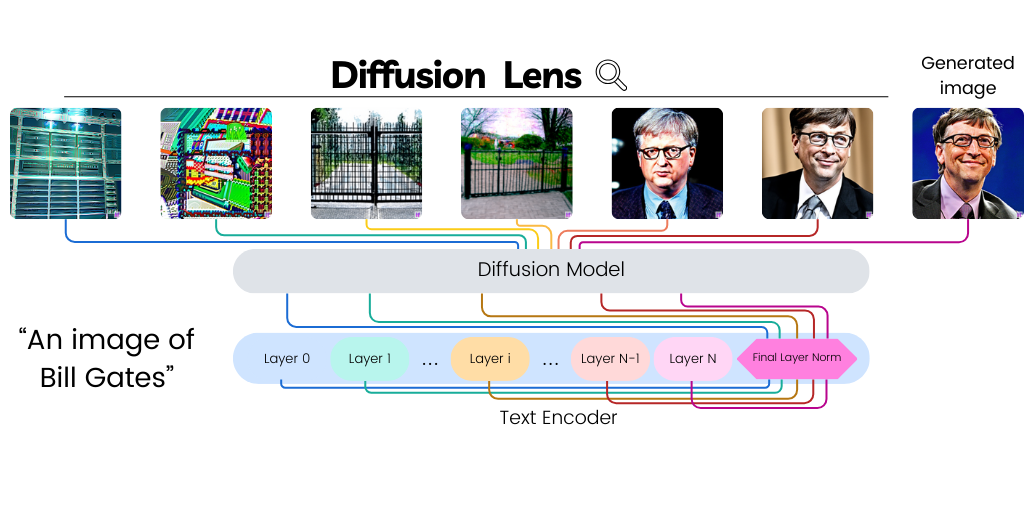
Diffusion Lens: Interpreting Text Encoders in Text-to-Image Pipelines
Michael Toker, Hadas Orgad, Mor Ventura, Dana Arad, Yonatan Belinkov, ACL, 2024 project page / video / arXiv Text-to-image diffusion models (T2I) use a latent representation of a text prompt to guide the image generation process. However, the process by which the encoder produces the text representation is unknown. We propose the Diffusion Lens, a method for analyzing the text encoder of T2I models by generating images from its intermediate representations. Using the Diffusion Lens, we perform an extensive analysis of two recent T2I models. Exploring compound prompts, we find that complex scenes describing multiple objects are composed progressively and more slowly compared to simple scenes; Exploring knowledge retrieval, we find that representation of uncommon concepts requires further computation compared to common concepts, and that knowledge retrieval is gradual across layers. Overall, our findings provide valuable insights into the text encoder component in T2I pipelines. |
Updates
- May 2026: DeLeaker poster at ICLR 2026 | Rio De Janeiro, Brazil.
- Aug 2025: Google Research Scientist Internship | TLV.
- May 2025: CulText2I oral at NAACL 2025 | Albuquerque, New Mexico.
- April 2025: NL-Eye poster at ICLR 2025 | Singapore.
- Jan 2025: Passed PhD Candidacy Exam.
- Oct 2024: I've received the VATAT Scholarship for outstanding women doctoral students in high-tech fields .
- Sep 2024: Outstanding TA Award for excellence as a Teaching Assistant in a Python course, CS Faculty.
Just a Bit About Me 🐾🎥📚🌍
Hi there! Beyond my research, I’m an animal lover and proud companion to the adorable fluffball:
 Guddi the cat
,
and the mischievous cutie
Guddi the cat
,
and the mischievous cutie
 Murphy the Border Collie
.
They definitely spice up our home-zoo dynamics!
Murphy the Border Collie
.
They definitely spice up our home-zoo dynamics!
I’m a foodie 🍲 who loves running 🏃♂️, movies 🎥, books 📚 and traveling 🌍✈️.
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |