Editor's Choice: Evaluating Abstract Intent in Image Editing through Atomic Entity Analysis
Abstract
Humans naturally communicate through abstract concepts like ``mood''. However, current image editing benchmarks focus primarily on explicit, literal commands, leaving abstract instructions largely underexplored. In this work, we first formalize the definition and taxonomy of abstract image editing. To measure instruction-following in this challenging domain, we introduce Entity-Rubrics, a framework that breaks down abstract edits into individual, entity-level assessments and achieves strong correlation with human judgment. Alongside this framework, we contribute AbstractEdit, the first benchmark dedicated to abstract image editing across diverse real-world scenes. Evaluating 11 leading models on this dataset reveals a fundamental challenge: standard architectures struggle to balance intent and preservation, commonly defaulting to under-editing or over-editing. Our analysis demonstrates that driving meaningful improvements relies heavily on integrating advanced LLM text encoders and iterative thinking. Looking forward, our entity-based paradigm can generalize beyond assessment to serve as a reward model, enable models to correctly interpret abstract communication, or highlight specific failures in test-time critique loops. Ultimately, we hope this work serves as a stepping stone toward seamless multimodal interaction, closing the gap between rigid machine execution and the natural, open-ended way humans communicate.
Abstract Image Editing

Human Intent Mapping in Image Editing

Entity-Rubrics Evaluation
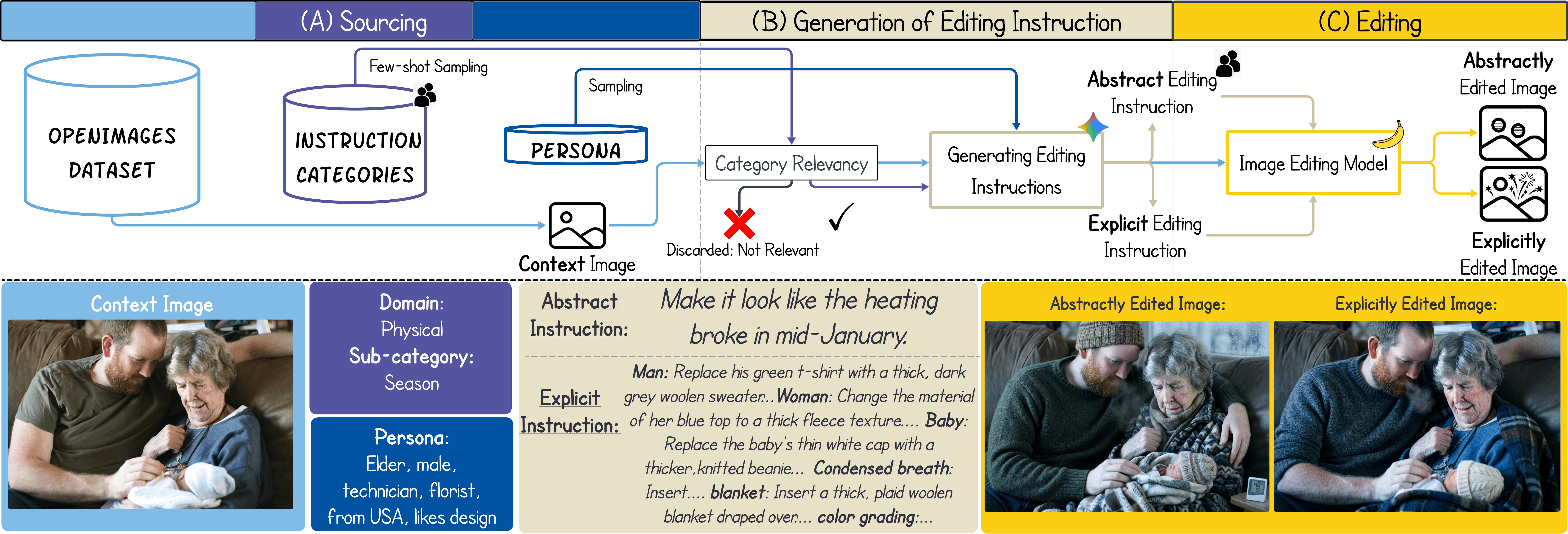
AbstractEdit Dataset Curation Pipeline
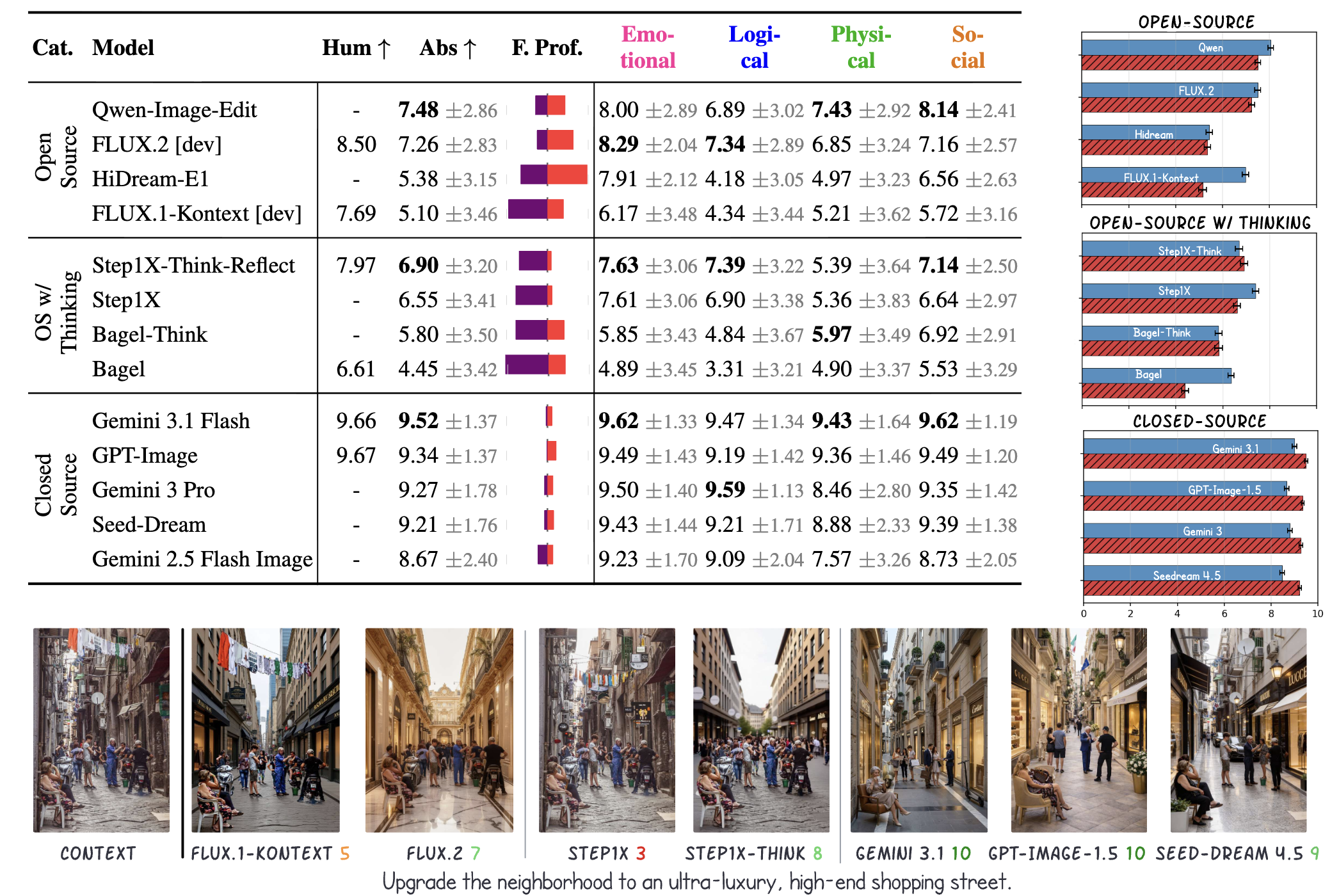
AbstractEdit Benchmark
Main Results
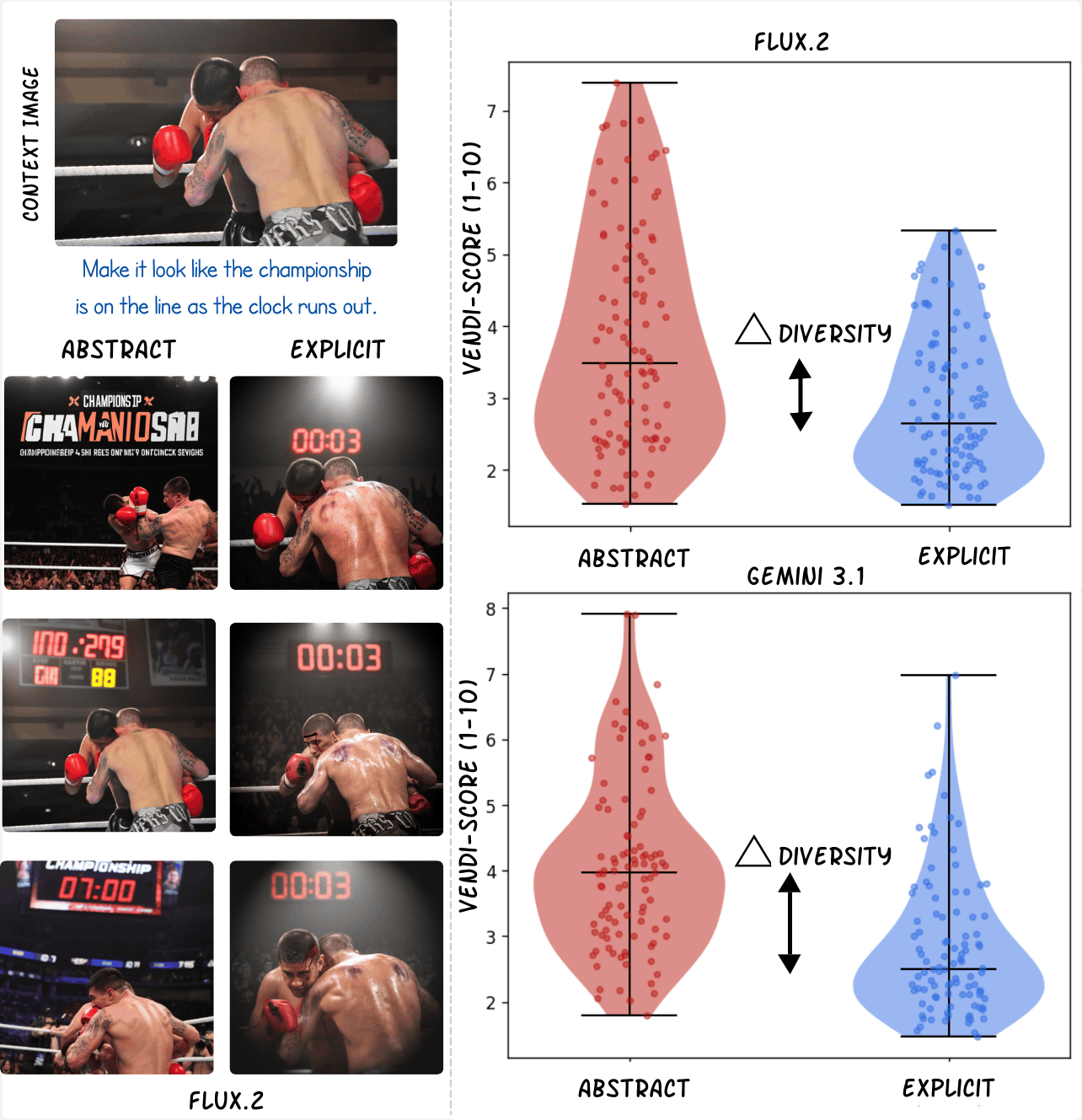
Model Diversity Analysis